Syntatic Analysis
4.1 Subphases of syntactic analysis
컴파일러 구문 분석은 아래와 같은 하위 과정으로 이뤄진다.
-
Scanning(or lexical analysis): 소스 프로그램 이 토큰의 스트림으로 변환하는 단계를 말한다. 이때 주석, 토큰 사이의 빈칸 들과 같은 필요 없는 요소는 버려진다.
-
Parsing: 구문 구조를 결정하기 위해 소스 프로그램을 파싱하는 단계를 말한다.
-
Representation of the phrase structure: 소스 프로그램의 구문 구조를 데이터 구조를 통해 나타내는 단계를 말한다. 이때 보통 AST가 사용된다.
4.1.1 Tokens
토큰(Token) 은 Scanner와 Parser 사이의 인터페이스이다.
‘Scanner’ - Token > ‘Parser’
토큰은 원자적 심볼. -> 의미 확인??
소스 프로그램은 토큰, 빈칸, 주석으로 이뤄진다. 하지만 블랭크, 주석 자체는 토큰은 아니다.
토큰은 용도에 따라 분류될 수 있다.
- 식별자
- 리터럴
- 오퍼레이터
같은 종류의 토큰은 다른 것으로 변경되어도 프로그램 구문 구조에 영향을 끼치지 않는다.
// 아래 서로 다른 토큰으로 이뤄져 있지만, 두 구문은 같은 구조이다.
var a : String
var b : Int
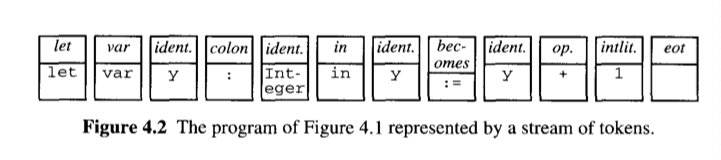
Example 4.2 Token of Mini-Triangle
각 토큰은 종류와 스펠링으로 완벽히 묘사 가능하다.
class Token(
val kind : Kind
val spelling : String
) {
enum class Kind {
IDENTIFIER,
INTLITERAL,
OPERATOR,
BEGIN,
CONST,
DO,
ELSE,
END,
IF,
IN,
LET,
THEN,
VAR,
WHILE,
SEMICOLON,
BECOMES,
IS,
LPAREN,
RPAREN,
EOT
}
}
각 토큰의 타입은 Parser에 의해 검사되며, 같은 타입의 다른 토큰은 구조엔 영향이 없다.
스펠링은 문맥검사 혹은 코드 제네레이터 단계에서 판단되는데, 이를 위해 스펠링 정보는 AST 만드는데까지 유지 되어야 한다.
4.2 Grammers revisited
4.2.1 Regular expressions
정규식(Regular expressions) 은 터미널 심볼의 조합을 표현하기 좋은 표기법이다. 주로 아래와 같은 기능이 있다.
A | B: A 대신 B 가능
A*: A가 0번 이상 반복될 수 있음
(,): 그룹핑

- empty : 빈 문자열
- singletone : 터미널 심볼
- concatienation : ‘A ‘B’ > ‘AB’
- alternative : ‘A’
|‘B’ > ‘A’ or ‘B’ - iteration : X, XX, XXX, XXXX …
- grouping : (‘XY’)* > XY, XYXY, XYXYXY …
Example 4.3 Regular expressions
‘M’ ‘r’
|‘M ‘s’ - {‘Mr’, ‘Ms’}‘M’ (‘r’
|’s’) - {‘Mr’, ‘Ms’}‘p’ ‘s’* ‘t’ - {pt, pst, psst, … }
‘b’ ‘a’ (‘n’ ‘a’)* - {‘ba’, ‘bana’, ‘banana’ … }
‘M’ (‘r’
|‘s’)* - {‘M’, ‘Mr’, ‘Ms’, ‘Mrr’, ‘Mrs’, ‘Msr’, ‘Mss’ … }
- Regular Language로는 간단한 언어만 표현 가능하다.
- Programming Language처럼 복잡하고 ‘self-embedding(자가 포함)’ 문법을 갖는 언어는 정규식만으로 표현 불가능 하다.
자가 포함 예시
- 표현식
'a * (b + c) / d'내부에(b + c)존재 가능. - 커맨드
if x > y then m := x else m := y내부에m := x커맨드 존재 가능.
프로그래밍 언어는 정규식만으로 표현이 불가능하며, BNF, EBNF를 이용해 재귀적 표현을 명시해야 함
4.2.2 Extended BNF
EBNF = BNF + RE
N ::= X
여기서 N은 논터미널 심볼, X는 터미널 심볼과 논터미널과 정규식 조합 구성됨
Exmaple 4.4 Grammar expressed in EBNF
Expression ::= primary-Expression(Operator primary-Expression)*
primary-Expression ::= Identifier
| ( Expression )
Identifier ::= a | b | c | d | e
Operator ::= + | - | * | /
e
`Expression` > `primary-Expression` > `Identifier`
a + b
`Expression` > `primary-Expression` `Operator` `primary-Expression` >
`Identifier` `Operator` `Identifier`
a + (b * c)
`Expression` > `primary-Expression` `Operator` `primary-Expression` >
`primary-Expression` `Operator` `(Expression)` >
`primary-Expression` `Operator` (`primary-Expression` `Operator` `primary-Expression`) >
`Identifier` `Operator` (`Identifier` `Operator` `Identifier`)
4.2.3 Grammar transformations
Left factorization
X Y | X Z==X (Y | Z)
Example 4.5 Left factorization
single-Command ::= V-name := Expression
| if Expression then single-Command
| if Expression then single-Command
else single-Command
// Left factorization 적용
single-Command ::= V-name := Expression
| if Expression then single-Command
(e | else single-Command)
Elimination of left recursion
N ::= X | N Y==N ::= X(Y)*
N Y > (N Y) Y > (N Y) Y Y > ... > XYYYYY => X(Y)*
Example 4.6 Elimination of left recursion
Identifier ::= Letter
| Identifier Letter
| Identifier Digit
// Left factorization 적용
Identifier ::= Letter
| Identifier (Letter | Digit)
// Elimination of left recursion 적용
Identifier ::= Letter (Letter | Digit)*
Example 4.7 Substitution
single-Command ::= for Control-variable := Expression To-or-Downto
Expression do single-Command
| ...
Control-Variable ::= Identifier
To-or-Downto ::= to
| downto
// Substitution 적용
single-Command ::= for Identifier := Expression (to | downto)
Expression do single-Command
치환(Substitution) 을 통해 불필요한 논터미널 심볼을 제거 할 수 있다.
4.2.4 Starter sets
starters[[X]]는 X의 구문구조들의 첫 터미널 심볼의 집합
Subject ::= I | a Noun | the Noun
starters[[Subject]] > {I, a, the}
4.3 Parsing
파싱(Parsing) 은 스캐닝 단계에서 얻어진 토큰 스트림을 통해 구문 구조를 발견하는 단계를 말한다.
- Recognition: 입력된 문자열이 어떠한 문법의 문장이 될 수 있는 지 결정
- Parsing: 입력된 문자열을 인식에 더해 구문 구조를 결정하는 것이다. 구문 구조는 신택스 트리로 표현 된다.
파싱 알고리즘은 여러가지 존재하지만, 이장에선 기본적인 아래의 2가지 알고리즘을 다룬다.
bottom-up parsing(상향식 파싱)
top-bottom parsing(하향식 파싱)
Example 4.8 Grammar of micro-English

the cat sees a rat. // OK
like cat. // Error
4.3.1 The bottom-up parsing strategy
Example 4.9 Bottom-up parsing of micro-English
the cat sees a rat .

(1) ‘the’로 이동 > 파서는 아직 아무것도 알 수 없다. > ‘cat’로 이동 > 프로덕션 룰 ‘Noun ::= cat’ 적용 가능 > cat을 하위 트리로 하는 Noun 트리 생성

(2) Subject ::= ‘the’ Noun 적용 가능 > Subject 트리 생성
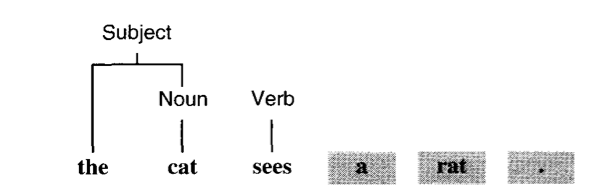
(3) ‘sees’로 이동 > ‘Verb ::= sees’룰 적용 > Verb 트리 생성

(4) ‘a’로 이동 > 할 수 있는 것 없음 > ‘rat’로 이동 > Noun룰 적용 > Noun 트리 생성

(5) Object룰 적용 > Object 트리 생성
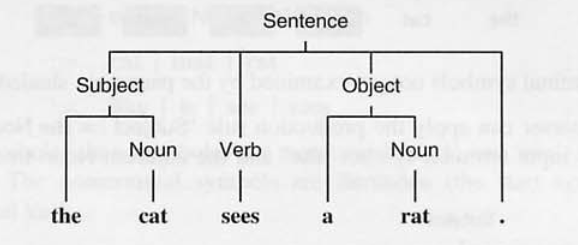
(6) ‘.’ 이동 > Sentence 룰 적용 > Sentence 트리 생성
일반적으로 상향식 파서는, 프로덕션룰의 오른쪽과 매칭되는, 터미널 심볼, 트리를 마주 했을때, 상위 트리로 조합된다.
(5)단계에서 Object가 아닌 Subject로 Tree를 만들었다면, 문제가 생긴다. 이렇게 각 단계에서 어떤 프로덕션 룰을 적용할지에 대해 상향식에선 판단하기 힘들다.
4.3.2 The top-down parsing strategy
Example 4.10 Top-down parsing of micro-English
the cat sees a rat .
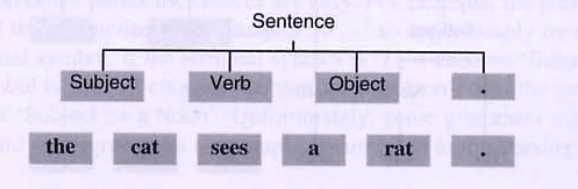
(1) 먼저 문장 노드에 적용할 룰을 찾는다 > 여기선 1개이므로, Sentence ::= Subject Verb Object.
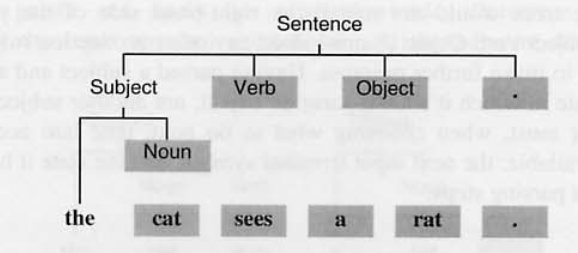
(2) 문장 구성의 제일 왼쪽부터 찾는다. > Subject를 구성할 수 있는 3가지 룰중 the Noun이 명백하므로 선택
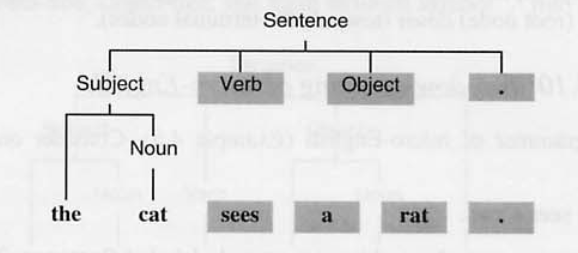
(3) 다음은 Noun을 구성하기 위한 값을 찾는다. > Noun ::= Cat > 트리 구성
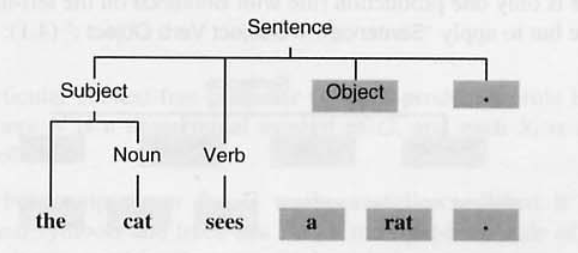
(4) Verb ::= sees > 트리 구성
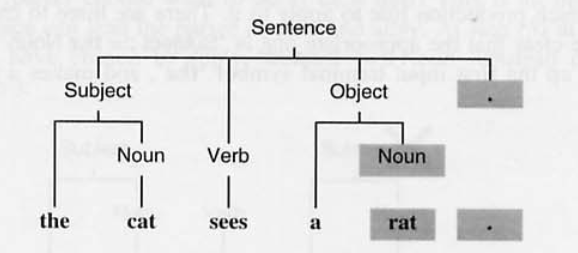
(5) Object ::= a Noun > 트리 구성

(6) Noun :: = rat > 트리 구성 > '.' 만나서 끝
하향식은 상향식과 같이 프로덕션 룰을 어떤것으로 적용할지 정하기 위해 이전 값들을 확인할 필요가 없다.
4.3.3 Recursive-decent parsing
Example 4.11 Recursive-descent parser for micro-English
class Parser(
val symbols: Queue<String>
) {
var currentSymbol : String? = symbols.poll()
private fun accept(expected: String) {
if(currentSymbol == expected) {
currentSymbol = nextInput()
} else {
throw java.lang.RuntimeException()
}
}
private fun nextInput(): String? {
return symbols.poll()
}
fun parseSentence () {
parseSubject()
parseVerb()
parseObject()
accept(".")
if(currentSymbol == null) {
println("compile complete")
} else {
println("compile error")
}
}
private fun parseSubject() {
if (currentSymbol == "I") {
accept("I")
} else if(currentSymbol == "a") {
accept("a")
parseNoun()
} else if (currentSymbol == "the") {
accept("the")
parseNoun()
} else {
throw java.lang.RuntimeException()
}
}
private fun parseNoun() {
if (currentSymbol == "cat") {
accept("cat")
} else if(currentSymbol == "mat") {
accept("mat")
} else if(currentSymbol == "rat") {
accept("rat")
} else {
throw java.lang.RuntimeException()
}
}
private fun parseVerb() {
if (currentSymbol == "like") {
accept("like")
} else if(currentSymbol == "is") {
accept("is")
} else if(currentSymbol == "see") {
accept("see")
} else if(currentSymbol == "sees") {
accept("sees")
} else {
throw java.lang.RuntimeException()
}
}
private fun parseObject() {
if (currentSymbol == "me") {
accept("me")
} else if(currentSymbol == "a") {
accept("a")
parseNoun()
} else if(currentSymbol == "the") {
accept("the")
parseNoun()
} else {
throw java.lang.RuntimeException()
}
}
}
Parser는 syntax tree를 만들지는 않지만, Parser 내부 함수 호출 구조가 tree와 동일하기에 만들떄 사용될 수 있다.
4.3.4 Systematic development of a recursive-descent parser
(1) 문법을 EBNF로 표현한다. 문법 변환을 통해 정리 (2) 각 룰을 parse메서드로 변경 (3) Parser 생성
Example 4.12
- EBNF 정리
Command ::= single-Command
| Command ; single-Command
// left recursion & Substitution
Command :: single-Command(; single-Command)*
- parsing method 구현
private fun parseProgram()
private fun parseCommand()
private fun parseSingleCommand()
private fun parseExpression()
private fun parsePrimaryExpression()
private fun parseDeclaration()
private fun parseSingleDeclaration()
private fun parseSingleDeclaration() {
when(currentToken.kind) { // single-declaration ::=
Token.CONST -> {
acceptIt() // const
parseIdentifier() // identifier
accept(Token.IS) // ~
parseExpression() // Expression
}
}
...
}
private fun parseCommand() { // Command ::=
parseSingleCommand() // single-command
when(currentToken.kind) {
Token.SEMICOLON -> { // (
acceptIt() // ;
parseSingleCommand() // single-command
} // )*
}
...
}
- Parser 구현
유의
- 토큰의 타입만 체크해야한다. 스펠링은 무시
- 프로그램끝에 EOT가 오는지 확인
- 각 구문분석 함수는 상호 재귀적이다.
위에서 작업했던 recursive-descent parser 개발 방법을 일반화

starters[[X]]로 프로덕션 룰 찾음
LL grammar
X | Y문법이 있다면, stater X stater Y는 겹치면 안됨- X는 X 토큰 셋과 겹치면 안됨 위의 조건을 만족하는 문법을 LL grammar라고 부른다.
4.4 Abstract syntax trees
- rescursive-decent-parser 는 sorce progradm 의 시작과 끝을 찾는다는 의미에서 프로그램의 구조를 결정한다.
- one-pass compiler
- syntactic analyze 은 contextual analyzer 과 code-generator 를 호출할 때를 알 수 있다.
- mutli-pass compiler
- syntactic analyze 은 소스 프로그램의 구문 구조를 명시적으로 나타내야한다.
- 이것을 여기에서는 AST 라고 표현한다.
4.4.1 Representation
- Example 1.5 의 Mini-Triangle AST 예시를 보여준다.
- Mini-Triangle abstract syntax

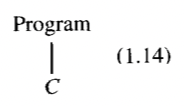
-
Command ASTs(C)

-
AssignCommand


- Node-tag 의 의미
- 각각의 AST 노드는 subtree 노드를 결정하는 태그를 가진다.
- ex) IfCommand 의 root 는 Command AST 이고,3개의 subTree 를 가지고 있다. expreesion AST 1개, Command AST 2개
-
Expression AST(E)
-
V-name AST
-
Declaration AST
-
Node-tag
- ConstDelcation 의 Root-tag 는 Declaration AST
- Identifier AST, Expression AST 로 구성되어짐
-
Type-denoter AST
- Node-tag
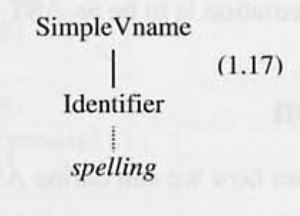
- ‘Identifier’ 태그가 있는 노드는 Identifier 의 root
- terminal node 이고, 내용은 spelling 뿐이다.






Java class 예시
- Mini-Traiangle AST 구조를 가지고 있는 Java 클래스를 정의 한다.
- 모든 abstract syntax tree 에 AST 추상 클래스를 호출한다.
public abstract class AST {}
- AST 의 모든 노드는, AST 하위 클래스의 객체이다.
public class Program extends AST {
public Command C;
/ / body of program
}
-
Program 은 single form 을 가지며, 명령어 인스턴스 변수인 C 로 구성되어 있다.
-
Command ASTs: Command class 에 세부적인 subclass 를 정의
public abstract class Command extends AST { ... )
public class AssignCommand extends Command {
public Vname V; / / left-side variable
public Expression E; / / right-side expression
}
public class CallCommand extends Command {
public Identifier I; / / procedure name
public Expression E; / / actual parameter
}
public class Sequentialcommand extends Command {
public Command C1, C2; / / subcommands
}
public class IfCommand extends Command {
public Expression E; / / if condition
public Command C1, C2; / / true and false commands
...
}
public class WhileCommand extends Command {
public Expression E; / / loop condition
public Command C / / body of loop
...
}
public class LetCommand extends Command {
public Declation D; / / block declarations
public Command C / / body of block
...
}
- Expression ASTs
public abstract class Expression extends AST { ... )
public class UnaryExpression extends Expression {
public Operator O; / / unary operator symbol
public Expression E; / / operand
}
public class BinaryExpression extends Expression {
public Operator O; / / binary operator symbol
public Expression E1, E2; / / left and right operands
}
- V-name ASTs:
- Declations ASTs
- Type-denoters AST
- Teirminal nodes
- Token(identifier, interger-literal, or operator) 과 일치한다.
- token 과 유사하다.
- token 의 spelling 을 가지고 있다.
public abstract class Terminal extends AST {
public String spelling; // token spelling from scanner
}
public class Identifier extends Terminal { ... }
public class IntergerLiteral extends Terminal { ... }
public class Operator extends Terminal { ... }
- 각각의 세부 클래스에서 적절한 생성자를 구성해야 한다.
public class AssignCommand (Vname v, Expresion E) {
this.V = V;
this.E = E;
}
public Identifier (String spelling) {
this.spelling = spelling
}
- syntatic constructor (구문 생성자) 를 AST 로 만들기 위해, 세부 클래스에 생성자에 클래스가 있는 파서를 정해야 한다.
4.4.2 Constrouction
- Mini-Traiangle parser 개선
private Program parseprogram ( ) ;
private Command parseCommand ( ) ;
private Expression parseExpression ( ) ;
private Declaration parseDeclaration ( ) ;
private TypeDenoter parseTypeDenoter ( ) ;
private Identifier parseIntegerLiteral ( ) ;
private Operator parseOperator ( ) ;
- parseSingleDeclaration
private Declaration parseSingleDeclaration ( ) {
Declaration declAST;
switch (currentToken.kind) {
case Token.CONST: {
acceptIt( ) ;
Identifier iAST = parseIdentifier0 ;
a c c e p t ( T o k e n .I S ) ;
Expression eAST = parseExpression( ) ;
declAST = new ConstDeclaration(iAST,eAST);
1
break ;
case Token.VAR: { acceptIt( ) ;
Identifier iAST = parseIdentifier( ) ;
accept(Token.COL0N);
TypeDenoter tAST = parseTypeDenoter( ) ;
declAST = new VarDeclaration(iAST,tAST);
1
break ;
default :
report a syntactic error
}
return declAST
}
- AST 가 로컬 변수인 declAST 를 사용함으로써 향상되었다고 볼 수 있다.
- 해당 메소드는 AST 의 결과 값을 반환한다.
-
지역 변수인 iAST,eAST, tAST 는 단일 선언된 AST 를 포함하기 위해 사용된다.
- 향상된 parseCommand
private Command parsecommand ( ) {
Command clAST = parseSingleCommand();
while (currentToken.kind== Token.SEMICOLON) {
acceptIt( ) ;
Command c2AST = parseSingleComrnand();
clAST = new SequentialCommand(clAST, c2AST);
}
return clAST;
}
- AST 를 올바른 구조로 구성하는데 주의해야 한다.
- clAST는 AST 를 값을 쌓기 위해 사용 된다.
4.5 Scanning
-
목적
- source program 에서 token 을 인지하기 위함이다.
-
parsing 과 유사하지만, 조금더 자세하다.
-
parsing 과 차이점
- parsing 은 terminal symbols 은 token 이고, expression command 나 좀더 큰 범위에서 그룹화
- scan 은 terminal symbols 은 토큰으로 그룹화 되어 있는 chararcter 이다.
- Seperactor
- 예시
- 공백, 주석
- 역할
- token 을 분리한다.
- 프로그램을 읽을때 보조한다.
- parser 와 같은 방법으로 scanner 를 개발할 수 있다.
- lexical grammer
- terminal symbols
- nontermianl symbols
- token
- sperator
- individual character
4.2.1 Scanner for Mini-triangle

- Mini-triangle 에 token sperator 규칙을 추가한다.
- space
- eol : end-of-line ‘character’
- eot : end-of-text ‘character’